Building Open Vernacular AI Kit: A Practical Preprocessing Layer for Indian Language AI
The Production Gap
Most AI pipelines look great in demos and break in production for one simple reason: real user text is messy.
People do not write in one language, one script, or one style. A single sentence can include Gujarati and English, Romanized words and native script, shorthand spellings, and dialect variations.
That mess directly hurts:
- retrieval quality
- intent routing
- LLM response reliability
- analytics consistency
I built Open Vernacular AI Kit to solve this exact layer.
The KLYRO Approach
Instead of forcing every downstream component to handle linguistic chaos, the idea is simple: normalize early, standardize once, improve everything downstream.
Problem: Noisy code-mix + script drift + spelling variance
Solution: A dedicated preprocessing layer before model calls
Result: Cleaner retrieval, routing, prompts, and analytics
What Problem This Project Solves
If you run support bots, search, or assistants for Indian users, you have likely seen this:
- same intent written in many spellings
- mixed scripts in a single sentence
- language boundaries that are unclear at token level
- poor matching in retrieval because query text and knowledge base text do not align
What Is Open Vernacular AI Kit?
Open Vernacular AI Kit is an open-source toolkit focused on code-mix normalization for production AI workflows.
It includes:
- API endpoints:
/normalize,/codemix,/analyze - Dockerized service mode for deployment
- CLI and integration recipes
- schema versioning for safer API evolution
- backward compatibility tests
- language-pack interface for scalable language support
- benchmark snapshots and evaluation slices
Why This Matters for LLM and RAG Systems
When query text is normalized before embedding and routing:
- retrieval overlap improves
- language-mix signals get cleaner
- LLM prompts become more structured
- support and search systems become more predictable
This is not about replacing your model. It is about helping your existing model stack perform better with real-world vernacular input.
Quick Start
git clone https://github.com/SudhirGadhvi/open-vernacular-ai-kit.git cd open-vernacular-ai-kit docker build -t open-vernacular-ai-kit . docker run -p 8000:8000 open-vernacular-ai-kit
Example API call:
curl -X POST http://localhost:8000/normalize \
-H "Content-Type: application/json" \
-d '{
"text": "che gujarat kayu nu paatnagar",
"lang": "gu"
}'You can also inspect code-mix and language signals through /codemix and /analyze.
Demo Screenshots
1) Landing / value overview

What this shows:
- the app focus: normalize mixed vernacular and English text before LLM/search/routing
- product value areas: LLM quality, retrieval quality, and analytics cleanup
- the starting point before running analysis
2) Live analysis (Before -> After)

What this shows:
- a raw romanized message in Before
- canonicalized output in After with native-script conversions
- conversion metrics (romanized tokens, converted count, conversion rate, backend)
- token-level changes for transformation inspection
3) RAG section

What this shows:
- the India-focused mini-KB retrieval panel
- query input, preprocessing toggle, embeddings mode, and top-k controls
- a quick way to test retrieval quality on canonicalized inputs
4) Settings panel (expanded)

What this shows:
- runtime controls for transliteration, numerals, backends, and model options
- Sarvam comparison toggles and advanced dialect-related settings
- the main place to configure behavior before analysis
5) Token LID panel (expanded)

What this shows:
- token-by-token language tags and confidence scores
- why each token was classified as native script, romanized, English, or other
- useful diagnostics for lexicon and transliteration rule debugging
6) Code-switching + dialect panel (expanded)
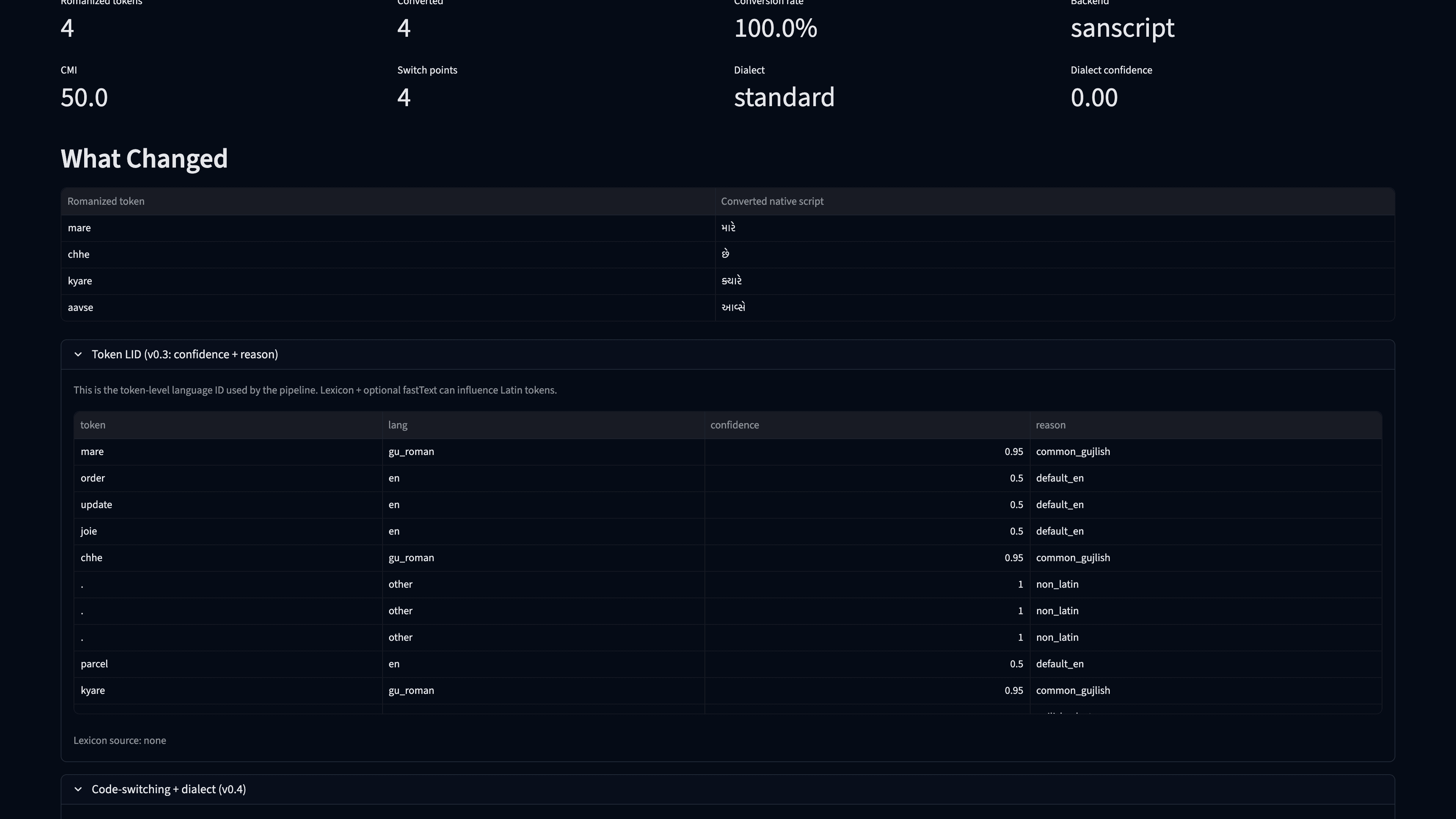
What this shows:
- CMI and switch-point metrics for mixed-language inputs
- detected dialect label and confidence
- quick diagnostics for mixed or dialect-heavy input
7) Batch helpers panel (expanded)

What this shows:
- CSV and JSONL upload flows for bulk preprocessing
- download-ready processed outputs for production pipelines
- the fastest way to run large batches through the same normalization logic
Project Direction and Engineering Priorities
Current focus is practical and measurable:
North-star metrics
- transliteration success
- dialect accuracy
- p95 latency
Language scalability without bloat
- language-pack interface
- Gujarati as reference
- Hindi beta support
- fail-safe fallback behavior
Developer adoption
- copy-paste integration examples
- RAG preprocessing recipes
- batch processing usage patterns
- before-vs-after output walkthroughs
Who Should Use This
- teams building support automation for Indian audiences
- product search and retrieval systems handling mixed-language input
- LLM app developers dealing with noisy multilingual user text
- AI infrastructure teams that want a clean preprocessing layer before model calls
Open Source First
This project is being built in public with a clear focus on:
- production reliability
- transparent benchmarks
- contributor-friendly architecture
- language expansion through modular packs
If you are building in this space, your feedback is valuable.
Try It and Contribute
GitHub: github.com/SudhirGadhvi/open-vernacular-ai-kit
If this helps your stack:
- open an issue with edge cases
- submit a language-pack improvement
- share benchmark ideas
- star the repo to support visibility
I am actively improving this with real-world usage signals, and I would love to collaborate.
Have feedback on multilingual AI preprocessing? Get in touch — I would love to hear from you.